Sonicry II
2026 | Performance


Overview
本作は、顔の表情変化と「泣くこと」をトリガーとして展開されるライブパフォーマンスである。本作において「泣く」という行為は、単なる情動の発露としてではなく、音楽を構成する構造的要素、時間的な変化、そして揺れ動く意味内容を内包した「音楽的素材」として扱われる。 演奏者はカメラの前で自身の内面と向き合い、涙を流す過程を通じて、その生理的・心理的な変化を即時的に音響信号へと変換する。これにより、「泣き」を即興的なパフォーマンスおよび創作行為として成立させることを試みている。
Process
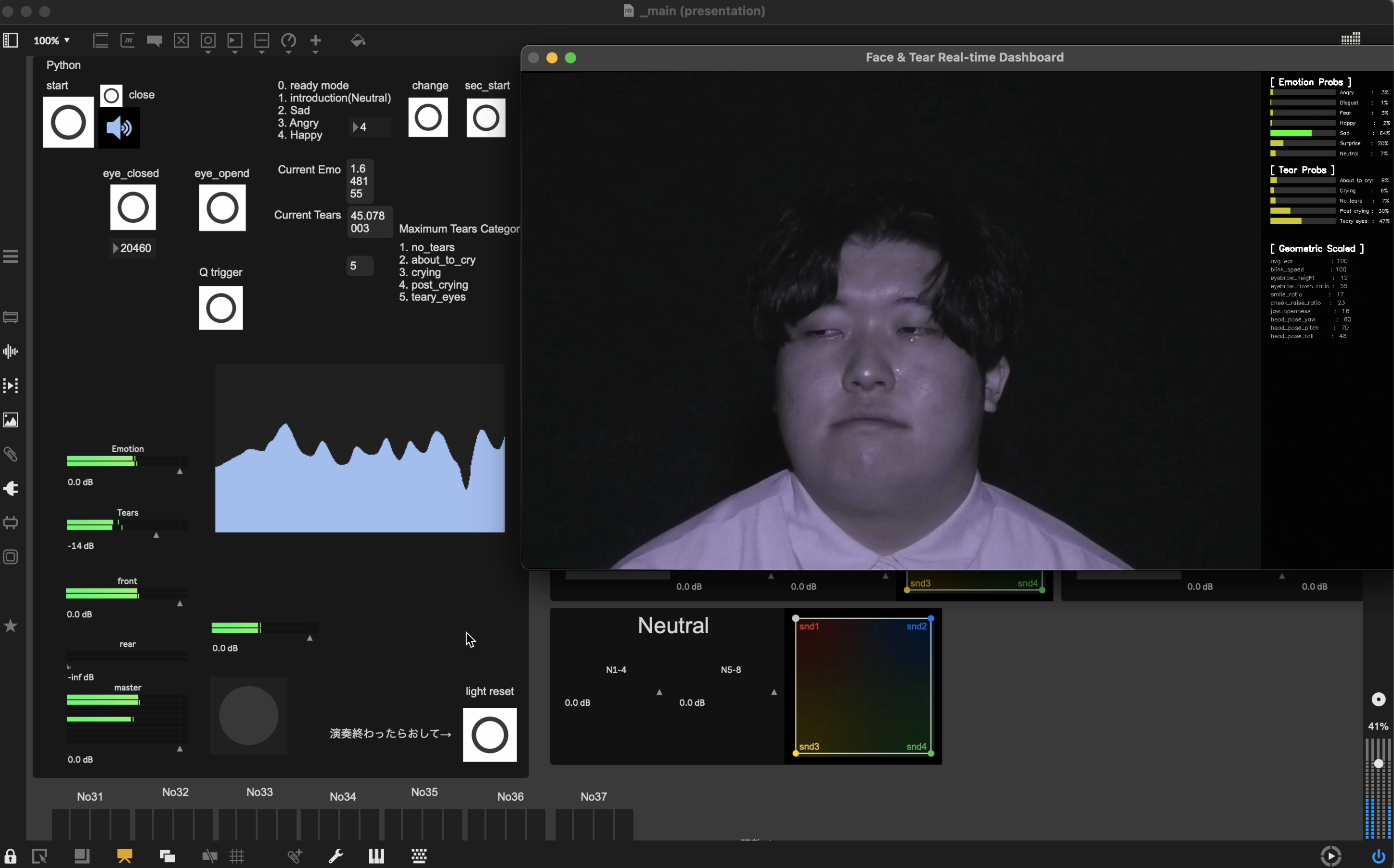
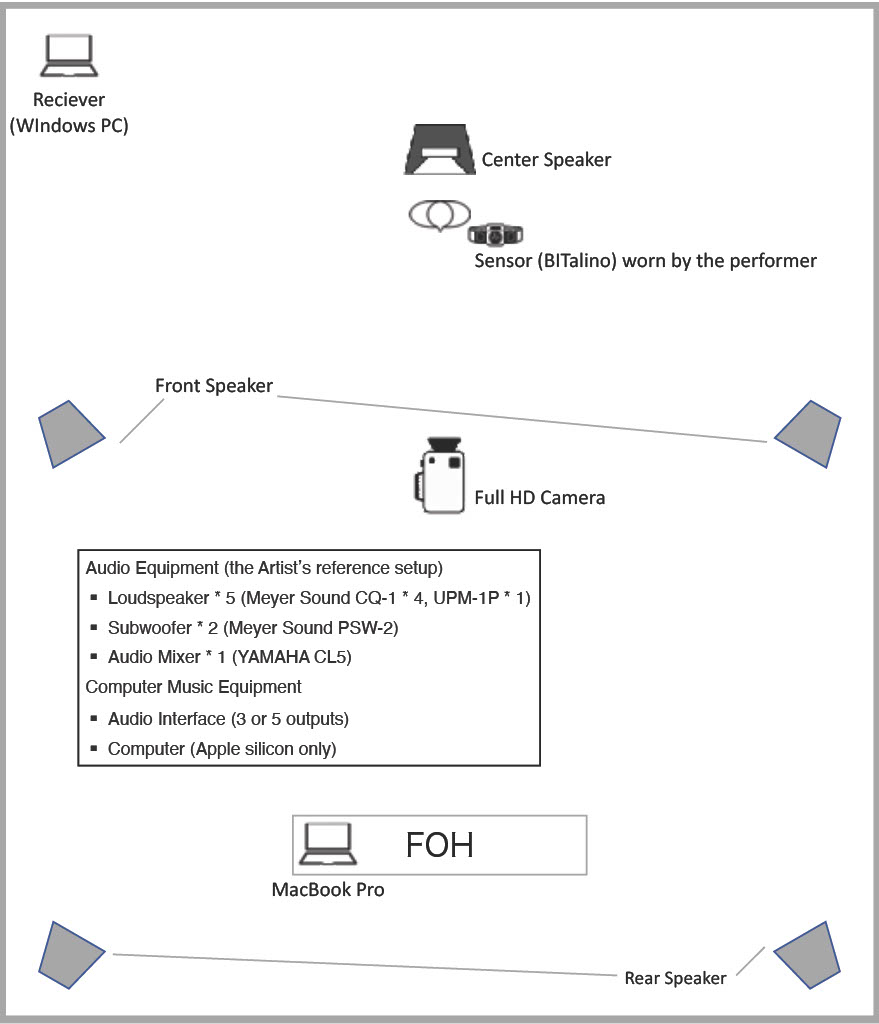
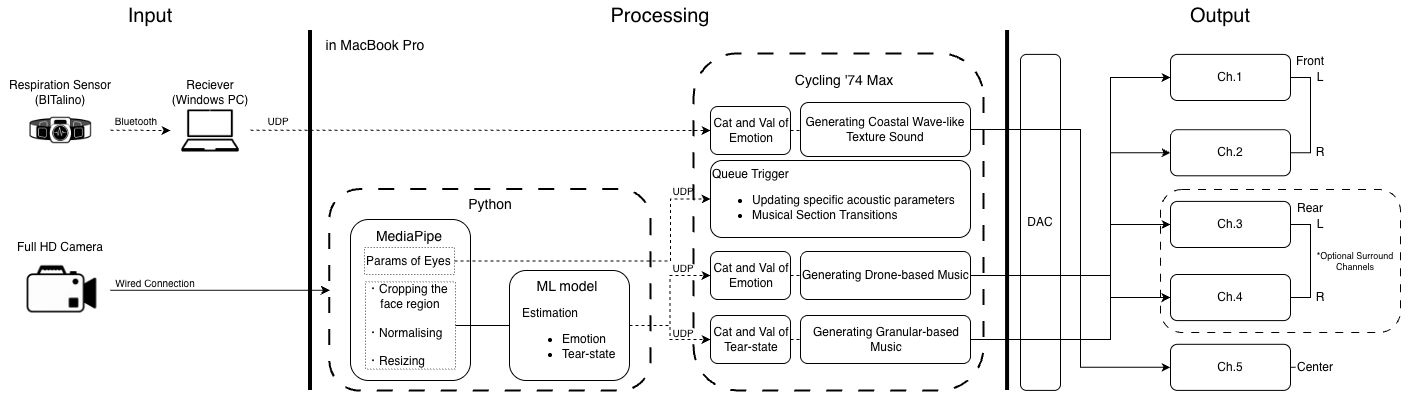
本システムは、大きく「特徴量抽出部(入力)」と「音響生成部(出力)」のフローで動作する。基盤技術として、自作の機械学習モデルを用いた感情クラス(7系統)および涙クラス(5系統)のマルチタスク推定を取り入れている。 モデルの学習にあたっては、AffectNetなどの大規模オープンデータセットや日本人に特化した顔画像データ、独自収集データを統合し、総計94,693点のデータセットを構築した。特徴抽出部にはImageNetで事前学習されたResNet50を採用し、中間特徴から感情用と涙用の独立した全結合層へ分岐させる構成とした。学習時には実運用における低照度環境を想定したデータ拡張(ColorJitter, Random Erasing等)や、クラス不均衡対策としてのWeighted Random Samplerを適用し、頑健性の向上を図っている。推論結果はフレーム単位で取得され、音楽的な反応性を高める目的から涙状態の確率分布に対して独自の補正(no_tearsの抑制や、初期的な涙兆候の確率値ブースト)を実施した上で、他の既存モデルとのアンサンブル内で基準的な推定結果を提供する役割を担わせている。 入力として顔面を捉えたカメラ画像と、装着したPZT呼吸センサからのデータを取得し、システムはこれらを「Emotions」「Tears」「Geometry」の3つのカテゴリに抽出・成形する。取得した特徴量は音響生成部へと送られ、各カテゴリごとに異なる音楽的要素として再構成される。 EmotionsおよびTearsのパラメータは「Musification」としての変換を行う。具体的には、推定された感情クラスと強度に応じてドローンを軸としたテープ素材の再生範囲を、涙状態の確率値の大きいクラスとその強度に応じてグラニュラーサンプリングを軸としたテープ素材の再生範囲を、それぞれスペクトルモーフィングにより漸次変化させる。 一方、Geometry(MediaPipeによる顔面ランドマークと呼吸周期)は「Sonification」としての変換を行う。具体的には、口角の上がり具合(smile_ratio)を直接的に単純な音響信号としてフィードバックさせるほか、呼吸周期をノイズを軸とした音響成分のフィルタリング機構と連動させることで、海辺で生じる波のようなテクスチャの生成を試みている。また、演奏中の瞼の動き(blink_speed)は、一部の音響パラメータの更新および作中のセクション移動の契機として機能する設計を採用している。